こんにちは。テクノロジーデザイン本部 技術部 開発課です。
ChatGPTをかわきりにさまざまなLLM(Large Language Model)がでてきて、最近ではMeta社のLlama3の発表などもありLLMやVLM(Vision and Language Model)などの生成AIに興味をもった方もおられるかと思います。
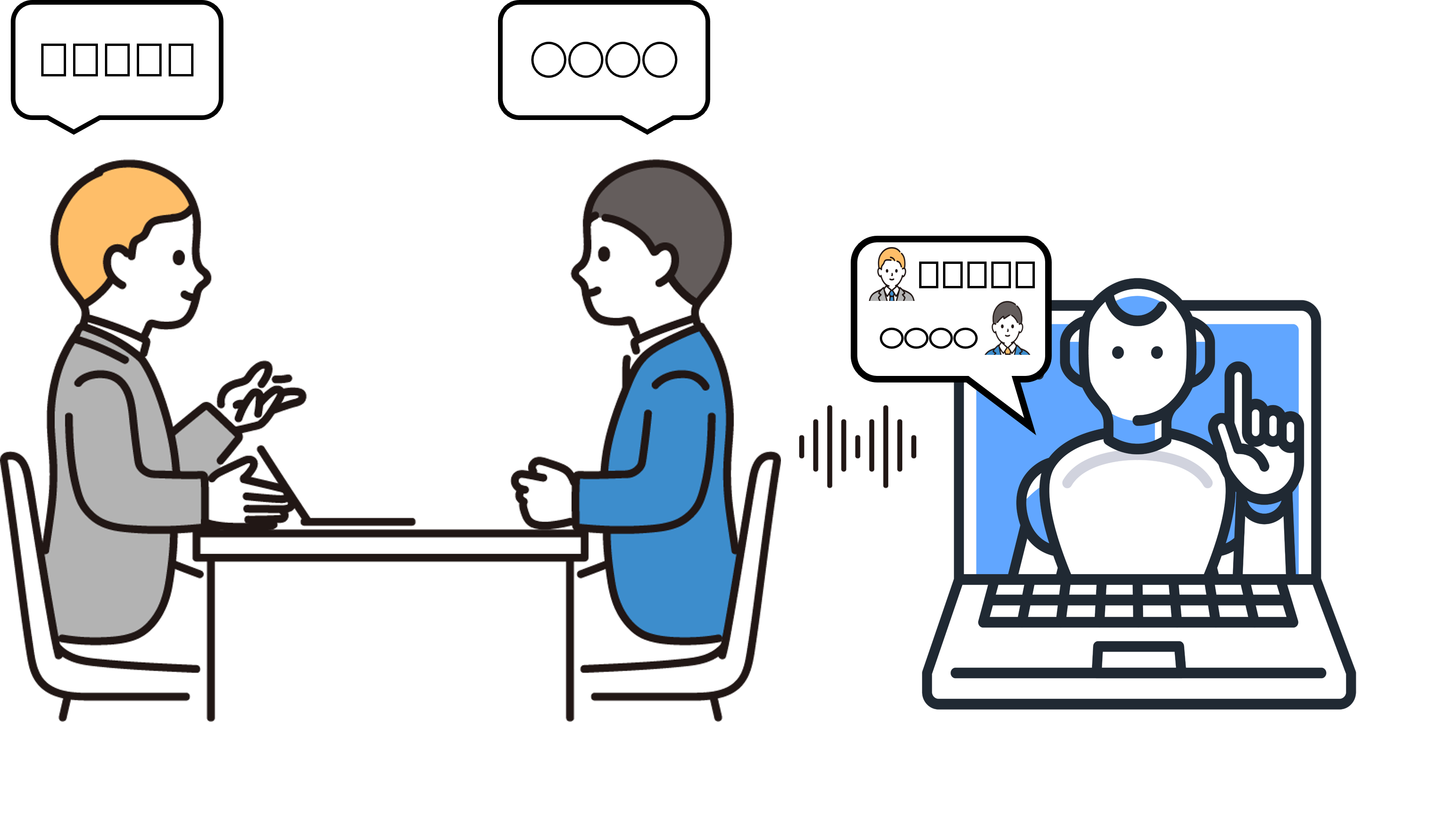
その状況下で、生成AIへの入力を音声から行う試みとしてJETSON OLIN AGXを使ってリアルタイムで文字起こしをご紹介したく、記事に纏めたいと思います。
はじめに
今回作成するのはJETSONにマイクを繋げて、録音した音声をWhisperで文字起こしを行います。
内容は以下のような感じでまずはシンプルに作成しようと思います。
音声取込み手法について
なにはともあれ音声を録音しないことには始まらないので、まずは音声を取込みするところから作成します。音声の取込みはpyaudioを使用しようと思いますのでまずはその環境の構築です。
pyaudioのインストールは下記のコマンドで行います。
portaudioというライブラリも必要なので、一緒にインストールしています。
sudo apt-get install portaudio19-dev
pip install pyaudio
音声の取り込みは以下のような感じです。
コールバック関数を用いてノンブロッキング処理で行っていますので、 音声録音中も他の処理が行えるようになります。
コールバック関数では取り込んだ音声データを予め用意していたキューに格納するだけにしています。
def start_recoding( self,in_device: int, in_rate: int, in_chank: int ):
“””
録音開始処理
“””
self._device = in_device
self._rate = in_rate
self._chunk = in_chank
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
input_device_index=self._device,
channels=1,
rate=self._rate,
input=True,
frames_per_buffer=self._chunk,
stream_callback=self._fill_buffer
)
self._audio_stream.start_stream()
self.closed = False
return
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
“””
オーディオストリームからのコールバック処理。録音データをキューに格納
“””
self._buff.put(in_data)
return None, pyaudio.paContinue
今回pyaudioのパラメータは以下のように設定しています。
| 項目 | 値 | 内容 |
|---|---|---|
| format | 16bit | 量子化ビット数 |
| channels | 1ch | チャンネル数 |
| rate | 16000 | サンプリング周波数 |
| input | True | 入力指定 |
| frames_per_buffer | 480 | バッファサイズ |
パラメータの内容を詳しく知りたい方は下記公式ページを見て頂ければと思います。 https://people.csail.mit.edu/hubert/pyaudio/docs/#
音声区間検出について
音の取り込みは行えましたが、文字起こしする為には人の音声が有る期間だけ録音する必要があります。
また長い音声の時はその分文字起こしまでに遅延が発生するのと文字起こしの処理に時間がかかることから、できれば音声を分割したいと思っています。
ただ時間で区切ってしまうと会話の途中で途切れてしまうので単純に分割することはできません。
いろいろと音声検出について調べるとVAD(Voice Activity Detection)と呼ばれる音声区間を検出する技術があるそうです。
Pythonのライブラリを探してみるとpy-webrtcvadというライブラリがありました。
py-webrtcvadはGoogle社が開発したWebRTC VADがベースになっており、ライセンスもMITライセンスで使いやすいことから今回このライブラリを使用しようと思います。
py-webrtcvadの仕様は以下の通りです。
- Modeは0~3までの4段階で、0が非音声のフィルタリングに抑制的で、3が積極的です
- 16bitモノラルPCMデータのみ対応
- サンプリングレートは8000,16000,32000,48000に対応
- フレームの時間は10,20,30msに対応
「py-webrtcvad」の詳細は下記GitHubを見て頂ければと思います。
https://github.com/wiseman/py-webrtcvad/tree/master
音声区間検出の実装
まずは環境構築ですがpy-webrtcvadのインストールは以下のコマンドで行います。
pip install webrtcvad
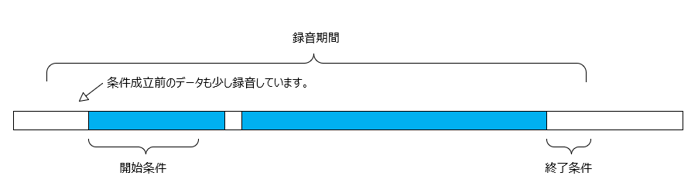
py-webrtcvadはシンプルで非音声か音声かを判定するのですが、1つのフレームが短い時間である事と実際動かしてみると人の音声以外でも反応しているので、録音開始・停止条件は以下のように過去数フレームの結果で判定しようと思います。
- 録音開始条件
カウンタを音声検出でインクリメント、非検出でデクリメントし、カウンタが20超え - 録音終了条件
非音声フレームが連続10回継続
実際のプログラムでは以下のようにしています。キューから取り込んだ音声データを取り出してpy-webrtcvadで音声の判定を行っています。
また録音期間中は音声データを結合しています。
def get_audio_data(self, start_thres:int, stop_thres: int) -> bytes:
if self.closed:
raise ValueError(“Not Open Device”)
data = []
speech_cnt = 0
silent_cnt = 0
is_start = False
while True:
try:
indata = self._buff.get(block=False)
is_speech = self.vad.is_speech( indata, self._rate )
# 録音開始前
if is_start == False:
# 音声データ結合
data.append( indata )
# 音声録音開始判定
if is_speech == True:
speech_cnt += 1
if speech_cnt >= start_thres:
is_start = True
else:
if speech_cnt > –5:
speech_cnt -= 1
if speech_cnt == –5:
data = []
# 録音中
else:
# 音声データ結合
data.append( indata )
# 音声録音終了判定
if is_speech == False:
silent_cnt += 1
if silent_cnt >= stop_thres:
break
else:
silent_cnt = 0
except queue.Empty:
pass
return data
録音時は上記関数で取得したデータをWAVファイルに保存します。
実際に弊社HPにある「社長メッセージ」の冒頭を読み上げて録音したWAVファイルは以下のような感じでした。
もう少し検証・調整の必要があると思いますが、現状上手く音声が分割できて録音しているようです。
さいごに
音声の録音ができましたので、次回はJETSONにて録音した音声の文字起こしをやっていきたいと思います。
(今回の記事でWhisperの記事を期待していた方すいません。後編までもう少しお待ちください)
関連製品


関連記事

参考文献
- PyAudio Documentation — PyAudio 0.2.14 documentation (mit.edu)
- GitHub – wiseman/py-webrtcvad: Python interface to the WebRTC Voice Activity Detector
更新履歴
2024/05/31 新規作成